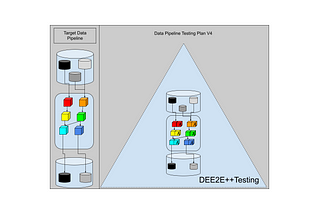
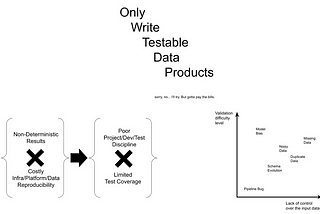
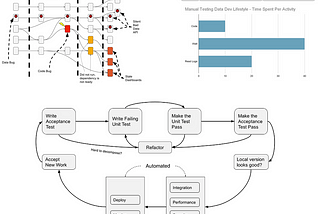
Moussa Taifi PhDinTowards Data ScienceEvolving a Data Pipeline Testing PlanThe Perils of Exhaustive Multi-Source Multi-Destination Test-Driven Development9 min read·Apr 30, 2023----
Moussa Taifi PhDModern Data Pipelines Testing Techniques: Why Bother? 3/3A Visual Guide.·8 min read·Jan 2, 2023----
Moussa Taifi PhDModern Data Pipelines Testing Techniques: Why Bother? 2/3A Visual Guide.7 min read·Jan 2, 2023----
Moussa Taifi PhDModern Data Pipelines Testing Techniques: Why Bother? 1/3A Visual Guide.8 min read·Jan 2, 2023----
Moussa Taifi PhDinTowards Data ScienceML Latency No MoreCommon Ways to Reduce ML Prediction Latency to Sub X ms·21 min read·Apr 25, 2022----
Moussa Taifi PhDinTowards DevSecuring Azure Synapse Workspaces? Beware of One Inescapable Networking Blocker.TLDR; No “Azure Synapse Serverless Spark Pool” Managed Outbound IP == No Ability to Filter Traffic to your Data Sources (as of 2021–12)·3 min read·Dec 16, 2021----
Moussa Taifi PhDinAWS TipKaggle for MLEs: Valuing ML System Robustness over TimeSomeone should build this.·4 min read·Nov 30, 2021----
Moussa Taifi PhDEvaluation Stores: Closing the ML Data Schwungrad?Model Stores, Feature Stores, Evaluation stores? Is the MLOps space going crazy, or is there a real need for these tools?·10 min read·Nov 29, 2021----
Moussa Taifi PhDinGeek CultureHow It Feels To Learn MLOps in 2021Disclaimer: No MLOps tools were harmed during the creation of this article.·12 min read·Nov 14, 2021--1--1
Moussa Taifi PhDHow Long Should It Take To Set Up a DS/ML CICD Pipeline on Azure Cloud?How long will it take me to set up a CICD pipeline for my data/ds/ml workflow on Azure Devops?·7 min read·Nov 12, 2021----